Sitzung 15 String manipulation
15.1 Vorbereitung
Für diese Lektion brauchen wir folgende Pakete:
library(tidyverse)
library(rvest)
library(sf)
library(rnaturalearth)15.2 Aufgabe
Ziel soll sein, aus Wikipedia eine Liste der Vulkane in Japan auszulesen und diese in einer Karte zu visualisieren, die mehr Informationen enthält als die auf Wikipedia angebotenen Optionen.
15.3 Tabellen aus Wikipedia laden
Mit rvest lässt sich eine Liste der Tabellen auslesen:
alle_tabellen <-
"https://en.wikipedia.org/wiki/List_of_volcanoes_in_Japan" %>%
read_html %>%
html_table15.4 Tabellen kombinieren
Die Tabellen 1, und 8 sind dabei ergänzende Elemente auf der Wikipedia-Seite und hier uninteressant:
alle_tabellen[c(1, 8)]
## [[1]]
## # A tibble: 2 × 1
## X1
## <chr>
## 1 Map all coordinates using: OpenStreetMap
## 2 Download coordinates as: KML
##
## [[2]]
## # A tibble: 4 × 2
## .mw-parser-output .navbar{display:inline;font-size:88…¹ .mw-parser-output .n…²
## <chr> <chr>
## 1 "Sovereign states" "Afghanistan\nArmenia…
## 2 "States withlimited recognition" "Abkhazia\nArtsakh\nN…
## 3 "Dependencies andother territories" "British Indian Ocean…
## 4 "Category\n Asia portal" "Category\n Asia port…
## # ℹ abbreviated names:
## # ¹`.mw-parser-output .navbar{display:inline;font-size:88%;font-weight:normal}.mw-parser-output .navbar-collapse{float:left;text-align:left}.mw-parser-output .navbar-boxtext{word-spacing:0}.mw-parser-output .navbar ul{display:inline-block;white-space:nowrap;line-height:inherit}.mw-parser-output .navbar-brackets::before{margin-right:-0.125em;content:"[ "}.mw-parser-output .navbar-brackets::after{margin-left:-0.125em;content:" ]"}.mw-parser-output .navbar li{word-spacing:-0.125em}.mw-parser-output .navbar a>span,.mw-parser-output .navbar a>abbr{text-decoration:inherit}.mw-parser-output .navbar-mini abbr{font-variant:small-caps;border-bottom:none;text-decoration:none;cursor:inherit}.mw-parser-output .navbar-ct-full{font-size:114%;margin:0 7em}.mw-parser-output .navbar-ct-mini{font-size:114%;margin:0 4em}vteList of volcanoes in Asia`,
## # ²`.mw-parser-output .navbar{display:inline;font-size:88%;font-weight:normal}.mw-parser-output .navbar-collapse{float:left;text-align:left}.mw-parser-output .navbar-boxtext{word-spacing:0}.mw-parser-output .navbar ul{display:inline-block;white-space:nowrap;line-height:inherit}.mw-parser-output .navbar-brackets::before{margin-right:-0.125em;content:"[ "}.mw-parser-output .navbar-brackets::after{margin-left:-0.125em;content:" ]"}.mw-parser-output .navbar li{word-spacing:-0.125em}.mw-parser-output .navbar a>span,.mw-parser-output .navbar a>abbr{text-decoration:inherit}.mw-parser-output .navbar-mini abbr{font-variant:small-caps;border-bottom:none;text-decoration:none;cursor:inherit}.mw-parser-output .navbar-ct-full{font-size:114%;margin:0 7em}.mw-parser-output .navbar-ct-mini{font-size:114%;margin:0 4em}vteList of volcanoes in Asia`Mit den restlichen Tabellen (2–7) wollen wir weiterarbeiten:
relevante_tabellen <- alle_tabellen[2:7]Zunächst sollen sie untereinader
(zeilenweise) in einen Datensatz kombiniert werden.
Das geht eigentlich mit dem Befehl bind_rows() ganz gut — allerdings müssen dafür die Spalten die selben Namen (hier gegeben) und die selben Typen haben (hier nicht gegeben).
relevante_tabellen %>%
bind_rows()
## Error in `bind_rows()`:
## ! Can't combine `..1$Elevation (m)` <character> and `..3$Elevation (m)` <integer>.In der 3. und 4. Tabelle haben nämlich die Spalten Elevation (m) und Elevation (ft) den Typ int, während sonst alles den Typ chr hat:
walk(relevante_tabellen, str, vec.len = 0)
## tibble [33 × 5] (S3: tbl_df/tbl/data.frame)
## $ Name : chr [1:33] ...
## $ Elevation (m) : chr [1:33] ...
## $ Elevation (ft): chr [1:33] ...
## $ Coordinates : chr [1:33] ...
## $ Last eruption : chr [1:33] ...
## tibble [87 × 5] (S3: tbl_df/tbl/data.frame)
## $ Name : chr [1:87] ...
## $ Elevation (m) : chr [1:87] ...
## $ Elevation (ft): chr [1:87] ...
## $ Coordinates : chr [1:87] ...
## $ Last eruption : chr [1:87] ...
## tibble [14 × 5] (S3: tbl_df/tbl/data.frame)
## $ Name : chr [1:14] ...
## $ Elevation (m) : int [1:14] NULL ...
## $ Elevation (ft): int [1:14] NULL ...
## $ Coordinates : chr [1:14] ...
## $ Last eruption : chr [1:14] ...
## tibble [12 × 5] (S3: tbl_df/tbl/data.frame)
## $ Name : chr [1:12] ...
## $ Elevation (m) : int [1:12] NULL ...
## $ Elevation (ft): int [1:12] NULL ...
## $ Coordinates : chr [1:12] ...
## $ Last eruption : chr [1:12] ...
## tibble [24 × 5] (S3: tbl_df/tbl/data.frame)
## $ Name : chr [1:24] ...
## $ Elevation (m) : chr [1:24] ...
## $ Elevation (ft): chr [1:24] ...
## $ Coordinates : chr [1:24] ...
## $ Last eruption : chr [1:24] ...
## tibble [11 × 5] (S3: tbl_df/tbl/data.frame)
## $ Name : chr [1:11] ...
## $ Elevation (m) : chr [1:11] ...
## $ Elevation (ft): chr [1:11] ...
## $ Coordinates : chr [1:11] ...
## $ Last eruption : chr [1:11] ...Hier ist es zunächst das einfachste, die Spalten in character strings umzuwandeln, um sie kombinieren zu können.
Für eine Spalte hieße das:
as.character(relevante_tabellen[[3]]$`Elevation (m)`)
## [1] "423" "11" "854" "758" "574" "-110" "851" "813" "-50" "432"
## [11] "99" "136" "508" "394"Für mehrere Spalten in einer Tabelle:
relevante_tabellen[[3]] %>%
mutate(across(c(2, 3), as.character))
## # A tibble: 14 × 5
## Name `Elevation (m)` `Elevation (ft)` Coordinates `Last eruption`
## <chr> <chr> <chr> <chr> <chr>
## 1 Aogashima 423 1388 32°27′N 13… AD 1785[† 1]
## 2 Bayonnaise Rocks 11 36 31°53′17″N… AD 1970[† 14]
## 3 Hachijōjima 854 2802 33°08′N 13… AD 1605[† 1]
## 4 Izu-Ōshima 758 2507 34°43′34″N… Mt. Mihara: AD…
## 5 Kōzushima 574 1877 34°13′N 13… AD 838[† 1]
## 6 Kurose -110 -361 33°24′N 13… Caldera: older…
## 7 Mikurajima 851 2792 33°52′16″N… 6.3 ka BP[† 1]
## 8 Miyakejima 813 2674 34°05′10″N… AD 2013[† 16]
## 9 Myōjinshō (A.K.… -50 -164 31°55′05″N… AD 1970[† 1]
## 10 Niijima 432 1417 34°22′N 13… Mt. Mukaiyama:…
## 11 Sofugan (A.K.A.… 99 325 29°47′35″N… (Discolored wa…
## 12 Sumisujima (A.K… 136 446 31°26′20″N… AD 1916[† 1]
## 13 Toshima 508 1667 34°31′N 13… 9.1-4.0 ka BP[…
## 14 Torishima (A.K.… 394 1293 30°29′02″N… AD 2002[† 1]Über mehrere Tabellen, mit gleichzeitigem Kombinieren:
komplett <-
relevante_tabellen %>%
map(mutate, across(c(2, 3), as.character)) %>%
bind_rows()
komplett
## # A tibble: 181 × 5
## Name `Elevation (m)` `Elevation (ft)` Coordinates `Last eruption`
## <chr> <chr> <chr> <chr> <chr>
## 1 Akaigawa Caldera 725 2379 .mw-parser… 1.3 Ma BP[† 1]
## 2 Daisetsuzan Vol… 2290 7513 43°39′47″N… AD 1739[† 1]
## 3 Mount Eniwa 1320 4331 42°47′35″N… AD 1707 [† 1]
## 4 Mount E 613 2028 41°48′14″N… AD 1874[† 1]
## 5 Mount Iō 512 1680 43°36′36″N… Not known[† 1]
## 6 Akan Caldera [j… - - 43°27′04″N… 0.25 Ma BP[† 1]
## 7 Mount Meakan 1499 4916 43°23′10″N… AD 2008[† 1]
## 8 Mount Oakan 1370 4495 43°27′11″N… 5 ka BP[† 1]
## 9 Mount Iō 1563 5128 44°07′52″N… AD 1936[† 1]
## 10 Kussharo Caldera - - 43°37′16″N… 2.3 ka BP[† 1]
## # ℹ 171 more rows15.5 Tabellen säubern
15.5.1 Parse number
Für einige Spalten (Höhe, Koordinaten, letzte Aktivtät) ist ein numerisches Format aber eigentlich tatsächlich wünschenswert.
Eine robuste Möglichkeit dafür ist parse_number():
parse_number("Temperatur: -8° C")
## [1] -8Mit dem Befehl mutate() lassen sich neue Spalten erstellen, oder vorhandene Spalten überschreiben. Mit select() können Spalten selektiert oder (mit einem -) ,gelöscht‘ werden.
Der folgende Befehl wandelt die Spalte Elevation (m) in Zahlen um, gibt dieser neuen Spalte den Namen elevation_m und selektiert dann alles außer den alten Elevation-Spalten:
vulkane_elev <-
komplett %>%
mutate(elevation_m = parse_number(`Elevation (m)`)) %>%
select(-`Elevation (m)`, -`Elevation (ft)`)Wobei das Attribut problems
darauf hinweist, dass in manchen Strings keine Zahl gefunden wurde. Funktioniert hat es trotzdem (mit NA für fehlende Werte).
vulkane_elev
## # A tibble: 181 × 4
## Name Coordinates `Last eruption` elevation_m
## <chr> <chr> <chr> <dbl>
## 1 Akaigawa Caldera .mw-parser-output .ge… 1.3 Ma BP[† 1] 725
## 2 Daisetsuzan Volcanic Group 43°39′47″N 142°51′14″… AD 1739[† 1] 2290
## 3 Mount Eniwa 42°47′35″N 141°17′06″… AD 1707 [† 1] 1320
## 4 Mount E 41°48′14″N 141°09′58″… AD 1874[† 1] 613
## 5 Mount Iō 43°36′36″N 144°26′17″… Not known[† 1] 512
## 6 Akan Caldera [ja] 43°27′04″N 144°06′36″… 0.25 Ma BP[† 1] NA
## 7 Mount Meakan 43°23′10″N 144°00′29″… AD 2008[† 1] 1499
## 8 Mount Oakan 43°27′11″N 144°09′47″… 5 ka BP[† 1] 1370
## 9 Mount Iō 44°07′52″N 145°09′54″… AD 1936[† 1] 1563
## 10 Kussharo Caldera 43°37′16″N 144°20′10″… 2.3 ka BP[† 1] NA
## # ℹ 171 more rows15.5.2 Reguläre Ausdrücke
Spalten des Typs chr können außerdem mit Befehlen aus dem stringr-Paket (Teil von tidyverse) bearbeitet werden:
str_remove_all()entfernt Teile, die einem Muster entsprechenstr_extract_all()behält nur die Teile, die dem Muster entsprechenstr_detect()gibtTRUEaus, wenn das Muster gefunden wird, sonstFALSEstr_replace_all()ersetzt Teile, die dem Muster entsprechen, durch etwas anderes- etc.
Die Muster müssen dabei im RegEx-Format (regular expressions, reguläre Ausdrücke) angegeben werden. Reguläre Ausdrücke sind nicht R-spezifisch, sonderen kommen in allen geläufigen Programmiersprachen zum Einsatz.
Es kann eine große Herausforderung sein, ein RegEx-Muster zu basteln, das genau das macht, was man will. Dabei können browserbasierte Testumgebungen wie https://www.regexpal.com/ behilflich sein. Für einen systematischeren Zugang empfiehlt es sich, ein Tutorial wie https://regexone.com/ durchzuarbeiten.
Im folgenden Befehl werden reguläre Ausdrücke direkt in Kombination mit mutate() benutzt, um metrische Koordinaten zu extrahieren:
vulkane_geo <-
vulkane_elev %>%
mutate(
Coordinates = str_extract(Coordinates, "[0-9.]+; [0-9.]+"),
latitude = str_remove(Coordinates, "; [0-9.]+") %>%
as.numeric,
longitude = str_remove(Coordinates, "[0-9.]+; ") %>%
as.numeric
) %>%
select(-Coordinates)
vulkane_geo
## # A tibble: 181 × 5
## Name `Last eruption` elevation_m latitude longitude
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 Akaigawa Caldera 1.3 Ma BP[† 1] 725 43.1 141.
## 2 Daisetsuzan Volcanic Group AD 1739[† 1] 2290 43.7 143.
## 3 Mount Eniwa AD 1707 [† 1] 1320 42.8 141.
## 4 Mount E AD 1874[† 1] 613 41.8 141.
## 5 Mount Iō Not known[† 1] 512 43.6 144.
## 6 Akan Caldera [ja] 0.25 Ma BP[† 1] NA 43.5 144.
## 7 Mount Meakan AD 2008[† 1] 1499 43.4 144.
## 8 Mount Oakan 5 ka BP[† 1] 1370 43.5 144.
## 9 Mount Iō AD 1936[† 1] 1563 44.1 145.
## 10 Kussharo Caldera 2.3 ka BP[† 1] NA 43.6 144.
## # ℹ 171 more rowsEs gibt mehrere Formate, in denen die letzte Aktivität für die meisten Vulkane angegeben ist:
- AD … (Jahrszahl)
- … ka BP (vor soundsoviel tausend Jahren)
- … Ma BP (vor soundsoviel Millionen Jahren)
Einige Werte fallen dabei aus dem Rahmen, damit können wir aber leben.Außerdem können auch Zeiträume angegeben sein, oder verschiedene Werte von verschiedenen Bergen. Hier soll es aber darum gehen, nach Möglichkeit einen der angegebenen Werte auszulesen.
Für jedes mögliche Format wird dabei zunächst eine eigene numerische Spalte angelegt und umgerechnet in Jahre seit dem letzten Ausbruch
. Mit str_match können dafür Teile eines gefundenen Patterns extrahiert werden.
Schließlich wird mit pmin das Minimum der so gefundenen Werte ermittelt.
vulkane_geo %>%
mutate(ad_year = 2019 - str_match(`Last eruption`,
"AD ([0-9]+)")[,2] %>%
parse_number,
years_bp = str_match(tolower(`Last eruption`),
"([.0-9]+) bp")[,2] %>%
parse_number,
ka_bp = str_match(tolower(`Last eruption`),
"([.0-9]+) ka bp")[,2] %>%
as.numeric * 1000,
ma_bp = str_match(tolower(`Last eruption`),
"([.0-9]+) ma bp")[,2] %>%
as.numeric * 1000 * 1000,
years_since_last_eruption = pmin(ad_year,
years_bp,
ka_bp,
ma_bp,
na.rm = TRUE)) %>%
select(Name,
elevation_m,
latitude,
longitude,
years_since_last_eruption) -> vulkane_clean15.6 Visualisierung
Zunächst werden die Vulkane in eine Simple Feature Collection umgewandelt und das CRS gesetzt:
vulkane_clean %>%
st_as_sf(coords = c("longitude", "latitude")) %>%
st_set_crs(4326) -> vulkane_sfDas rnaturalearth Paket lässt uns einfach die Polygone für die japanischen Inseln laden:
japan <- ne_countries(scale = "medium",
country = "Japan",
returnclass = "sf")Dann lässt sich eine schnelle Karte zeichnen durch:
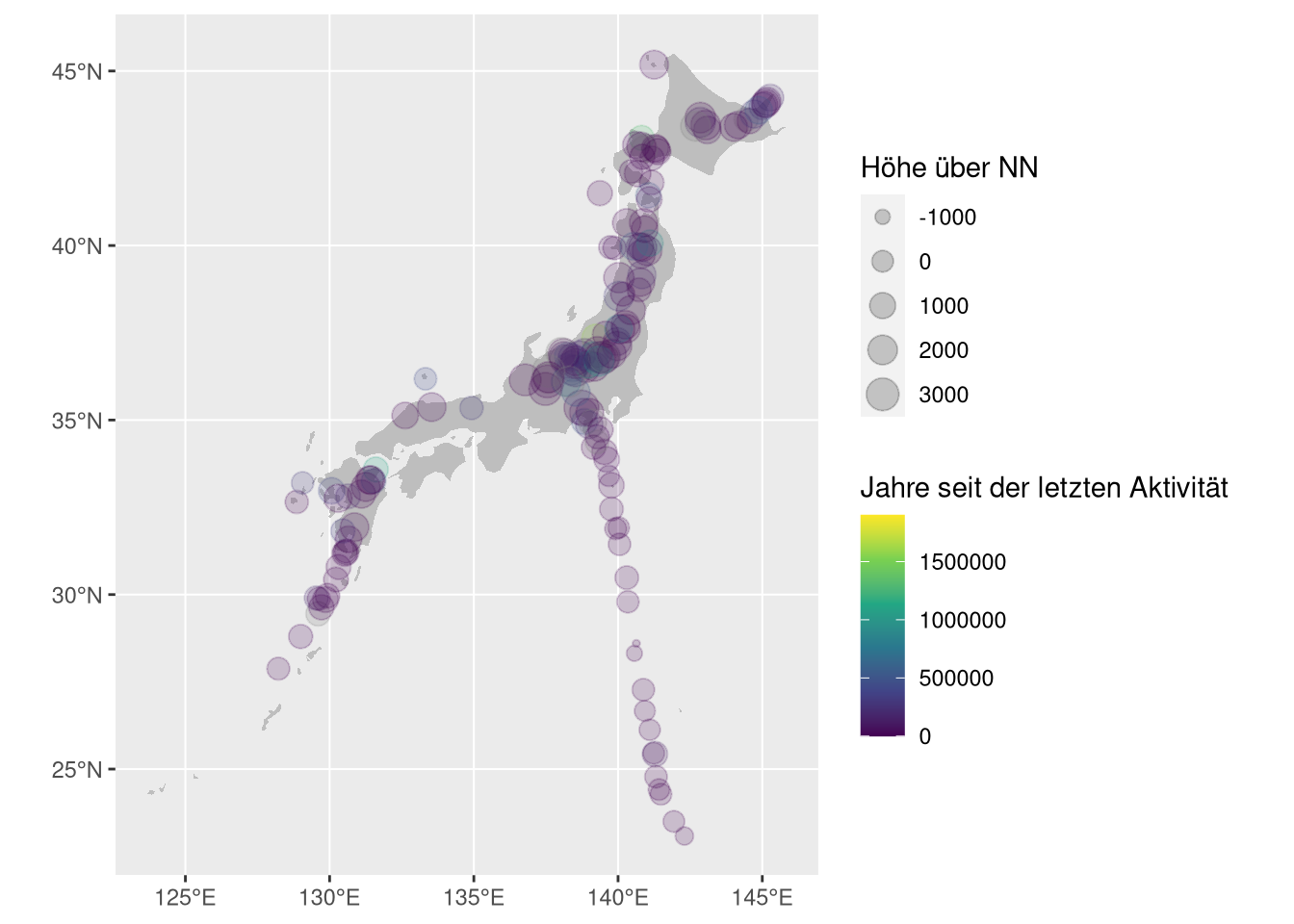
ggplot() +
geom_sf(data = japan, fill = "gray", color = NA) +
geom_sf(data = vulkane_sf,
aes(color = years_since_last_eruption,
size = elevation_m),
alpha = 0.2) +
scale_colour_viridis_c("Jahre seit der letzten Aktivität") +
scale_size_continuous("Höhe über NN")