Sitzung 16 Join und group
16.1 Vorbereitung
Für diese Lektion brauchen wir folgende Pakete:
library(tidyverse)
library(sf)
library(tmap)16.3 Daten einlesen
Das Tankerkönig
-Projekt veröffentlicht aktuelle Tankstellenpreise über eine API, und stellt historische Preise hier bereit: https://dev.azure.com/tankerkoenig/_git/tankerkoenig-data
Wir laden die Dateien für prices und stations von einem Tag (hier: 6.5.2023) herunter und speichern sie im Unterordner resources des Projektordners.
Dann können wir sie einlesen:
preise <- read_csv("resources/2023-05-06-prices.csv")
preise## # A tibble: 339,714 × 8
## date station_uuid diesel e5 e10 dieselchange e5change
## <dttm> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2023-05-05 22:00:14 4a6773b3-2c38-4… 1.52 1.89 0 0 1
## 2 2023-05-05 22:00:14 85f0cf5d-5c9b-4… 1.71 1.88 1.82 1 0
## 3 2023-05-05 22:00:14 e9a590a0-ec5f-4… 1.55 1.83 1.77 1 1
## 4 2023-05-05 22:00:14 2b91e044-603e-4… 1.71 1.93 1.87 1 1
## 5 2023-05-05 22:00:14 92825bd9-b322-4… 1.56 1.80 1.74 1 1
## 6 2023-05-05 22:00:14 9876c291-7600-4… 1.70 1.94 1.88 1 1
## 7 2023-05-05 22:00:14 8f2e54d9-12b2-4… 1.67 1.87 1.81 1 1
## 8 2023-05-05 22:00:14 c7b1d8f5-30d8-4… 1.61 1.88 1.82 1 1
## 9 2023-05-05 22:00:14 eec42f8a-ea6f-4… 1.63 1.86 1.82 1 1
## 10 2023-05-05 22:00:14 b9f0f8fb-31c8-4… 1.51 1.77 1.71 1 0
## # ℹ 339,704 more rows
## # ℹ 1 more variable: e10change <dbl>16.4 Überblick verschaffen
Beim näherem Betrachten fällt auf, dass im Datensatz preise 339.714 Zeilen enthalten sind, in stations nur 16.878.
Das liegt daran, das für jede Station mehrere Preisupdates im Datensatz preise stehen, jedoch nur einmal die gleichbleibenden Informationen (Name, Marke, Adresse, Koordinaten) in stations.
Beide Datensätze sind über einen eindeutigen „Key“ verbunden: In preise heißt er station_uuid, in stations einfach nur uuid.
Um ein besseres Gefühl für den Datensatz zu bekommen, könnten wir uns z. B. anschauen, zu welcher Uhrzeit wie viele Preise aktualisiert wurden:
ggplot(preise) +
geom_histogram(aes(x = date))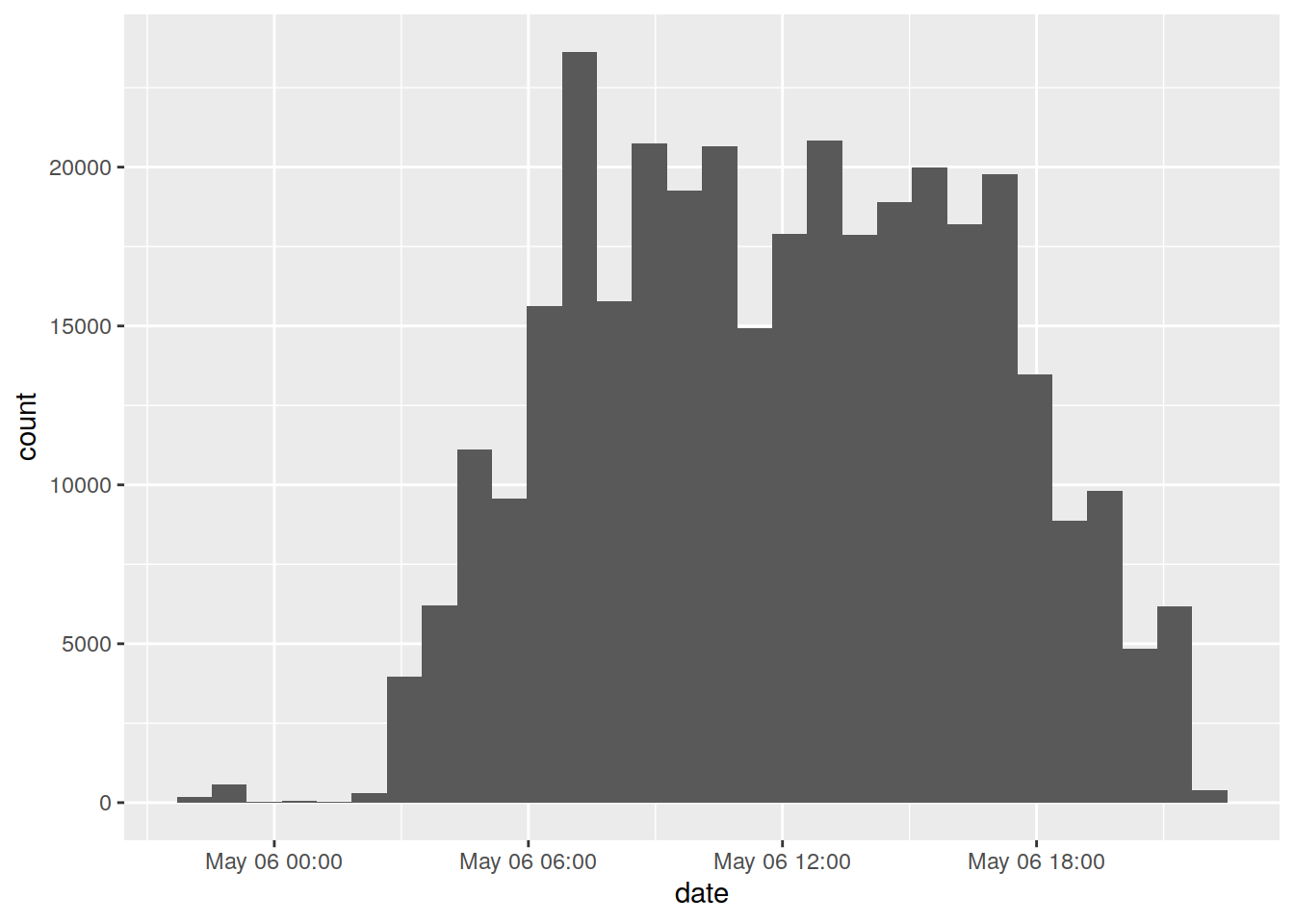
16.5 Zusammenfassen
Eine weitere Frage könnte sein: Wie sieht die Verteilung der Anzahl der Preisupdates je Tankstelle aus? Hierfür müssen wir den Datensatz preise anhand der Spalte station_uuid zusammenfassen und die Einträge zählen. Das geht mit group_by() und summarize():
preise %>%
group_by(station_uuid) %>%
summarize(anzahl_updates = n()) %>%
ggplot() +
geom_histogram(aes(x = anzahl_updates))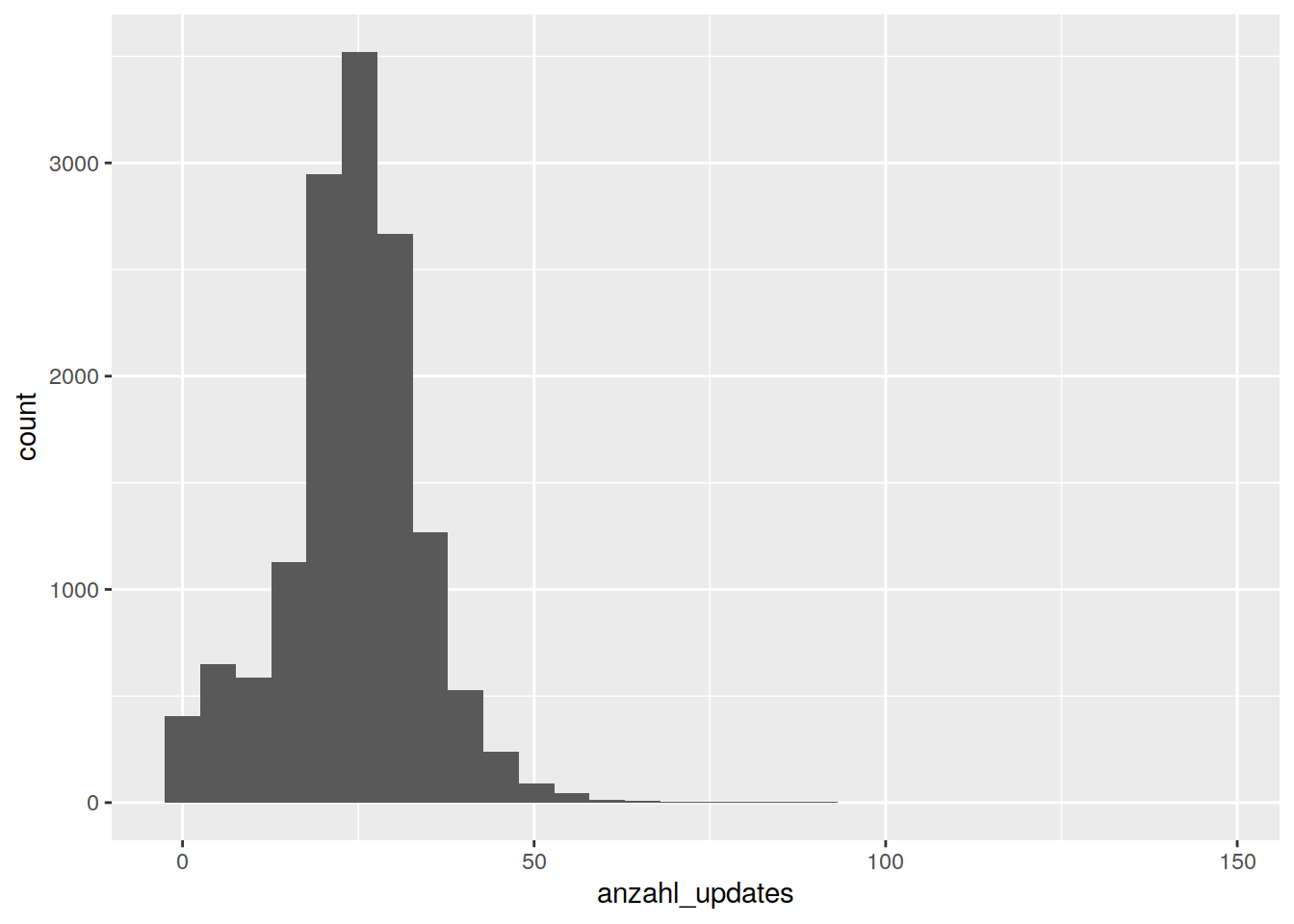
Um unserem Ziel der Dieselkarte etwas näher zu kommen, sollten wir aber nicht die Anzahl der Updates zusammenfassen, sondern den Dieselpreis.
Aber nach welchem Schema?
Einfach nur den Durchschnitt (mit mean()) zu nehmen, könnte das Bild verfälschen: Man stelle sich z. B. vor, ein besonders teurer (oder günstiger) Preis sei nur wenige Sekunden gültig gewesen.
Wir orientieren uns einfach an der Börse und nehmen einfach den letzten gültigen Preis (wie der Aktienwert bei Börsenschluss).
Dafür müssen wir den Datensatz erst mit arrange() chronologisch sortieren, dann entsprechend gruppieren und mit last() zusammenfassen:
preise_nach_tankstelle <-
preise %>%
arrange(date) %>%
group_by(station_uuid) %>%
summarize(dieselpreis = last(diesel),
e5preis = last(e5),
e10preis = last(e10))
preise_nach_tankstelle
## # A tibble: 14,114 × 4
## station_uuid dieselpreis e5preis e10preis
## <chr> <dbl> <dbl> <dbl>
## 1 00006210-0037-4444-8888-acdc00006210 1.62 1.85 1.81
## 2 00016899-3247-4444-8888-acdc00000007 1.71 1.88 1.83
## 3 00060001-d387-4444-8888-acdc00000001 1.54 1.87 1.81
## 4 00060014-b0d9-4444-8888-acdc00000002 1.61 1.85 1.79
## 5 00060015-0090-4444-8888-acdc00000090 1.53 1.80 1.74
## 6 00060029-0003-4444-8888-acdc00000003 1.51 1.79 1.73
## 7 00060039-63ad-4444-8888-acdc00000001 1.56 1.88 0
## 8 00060055-0001-4444-8888-acdc00000001 1.55 1.81 1.75
## 9 00060056-0001-4444-8888-acdc00000001 1.64 1.84 1.80
## 10 00060059-0004-4444-8888-acdc00000004 1.67 1.85 1.79
## # ℹ 14,104 more rows16.6 Verschneiden
Jetzt haben wir für jede Station nur noch eine Zeile mit den Preisen.
Um das zu kartieren, fehlen noch die Informationen zu den Tankstellen. Dafür laden wir auch den stations-Datensatz für den richtigen Tag herunter und importieren ihn in R:
tankstellen <- read_csv("resources/2023-05-06-stations.csv")
tankstellen## # A tibble: 16,878 × 11
## uuid name brand street house_number post_code city latitude longitude
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 44e2bdb7-… bft … <NA> Schel… 53 36304 Alsf… 50.8 9.28
## 2 ad812258-… bft … bft Godes… 55 53175 Bonn 50.7 7.14
## 3 0e18d0d3-… OIL!… OIL! Evers… <NA> 80999 Münc… 48.2 11.5
## 4 e1a15081-… Bode… HEM Polle… 3 37619 Bode… 52.0 9.51
## 5 e1a15081-… Biel… HEM Olden… 110 33604 Biel… 52.0 8.57
## 6 e1a15081-… Brau… HEM Bülte… 46 38106 Brau… 52.3 10.5
## 7 e1a15081-… Berl… HEM Riesa… 121 12627 Berl… 52.5 13.6
## 8 b4eefc41-… Spri… Spri… Bahnh… 29 39524 Sand… 52.8 12.0
## 9 e1a15081-… Berl… HEM Licht… 96 12279 Berl… 52.4 13.3
## 10 e1a15081-… Berl… HEM Berli… 320 13088 Berl… 52.6 13.5
## # ℹ 16,868 more rows
## # ℹ 2 more variables: first_active <dttm>, openingtimes_json <chr>Wir verschneiden mit inner_join() unter Angabe der relevanten Spaltennamen und wählen die Spalten aus, mit denen wir weiterarbeiten wollen:
preise_geo <-
inner_join(
preise_nach_tankstelle,
tankstellen,
join_by("station_uuid" == "uuid")
) %>%
select(
dieselpreis,
e5preis,
e10preis,
name,
brand,
latitude,
longitude
)
preise_geo
## # A tibble: 14,114 × 7
## dieselpreis e5preis e10preis name brand latitude longitude
## <dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl>
## 1 1.62 1.85 1.81 Beducker - Qualität gü… Bedu… 48.6 10.9
## 2 1.71 1.88 1.83 Röttenbach BFT … 49.7 10.9
## 3 1.54 1.87 1.81 Haisch Mineralölvertri… Tank… 48.0 7.59
## 4 1.61 1.85 1.79 Tank-Kontor Baienfurt <NA> 47.8 9.65
## 5 1.53 1.80 1.74 Schindele, Lochbrücke <NA> 47.7 9.53
## 6 1.51 1.79 1.73 rhv Tankstelle Raif… 50.5 9.72
## 7 1.56 1.88 0 Karl Daum Tankstelle P… <NA> 48.9 11.2
## 8 1.55 1.81 1.75 Wilhlem Heim GmbH Oel … 48.6 9.03
## 9 1.64 1.84 1.80 Tankstelle Kreidl <NA> 48.5 11.6
## 10 1.67 1.85 1.79 Bergler Mineralöl GmbH… Berg… 49.8 12.0
## # ℹ 14,104 more rowsinner_join hat die Besonderheit, dass nur Zeilen im kombinierten Datensatz übrigbleiben, deren Key in beiden Datensätzen gefunden wurde. Mit left_join würden hier alle Preise behalten werden (und die fehlenden Koordinaten mit NA ergänzt), mit right_join würden alle Stationen behalten werden (und fehlende Preise mit NA ergänzt). full_join löscht gar keine Informationen.
16.7 Kartieren
Den georeferenzierten Datensatz der Preise wandeln wir in eine Simple Feature Collection um:
preise_sf <-
preise_geo %>%
st_as_sf(coords = c("longitude", "latitude"))ggplot() kartiert so einen großen Datensatz nur langsam. Wir nehmen stattdessen das Paket tmap() zur Hand, das mit einer ähnlichen Grammatik funktioniert.
Interaktive Karten lassen sich mit tmap produzieren, wenn die Option
tmap_mode("view")gesetzt ist. Aus technischen Gründen wird an dieser Stelle im Skript darauf verzichtet und wir bleiben beim plot-Modus:
tm_shape(preise_sf) +
tm_dots()
Zwei Koordinaten sind quatsch! Wir finden ihre ungefähren Werte mit summary:
summary(preise_geo$longitude)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000 8.020 9.287 9.607 11.062 97.364Und filtern sie raus, und wiederholen die Umwandlung (diesmal auch mit CRS)
preise_sf <-
preise_geo %>%
filter(longitude < 80) %>%
st_as_sf(coords = c("longitude", "latitude")) %>%
st_set_crs(4326)Dann mappen wir nochmal:
tm_shape(preise_sf) +
tm_dots("dieselpreis", style = "cont")
Schon ganz hübsch, aber die Skala wird nun verzerrt durch sehr teure Autobahntankstellen einerseits, und falsche Null-werte andererseits:
summary(preise_sf$dieselpreis)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000 1.529 1.559 1.569 1.609 2.30916.8 Choroplethen
Eine Lösung wäre, die Daten auf Kreisebene zusammenzufassen, und zwar anhand ihres Medians. Damit würden diese Ausreißer keine Role mehr spielen.
Das eurostat-Paket macht es einfach, diese Geodaten einzulesen. NUTS3 ist die Ebene der Stadt- und Landkreise bzw. ihrer europäischen Equivalente.
kreise <- eurostat::get_eurostat_geospatial(nuts_level = 3) %>%
filter(CNTR_CODE == "DE")Mal schauen wie es aussieht:
tm_shape(kreise) +
tm_polygons()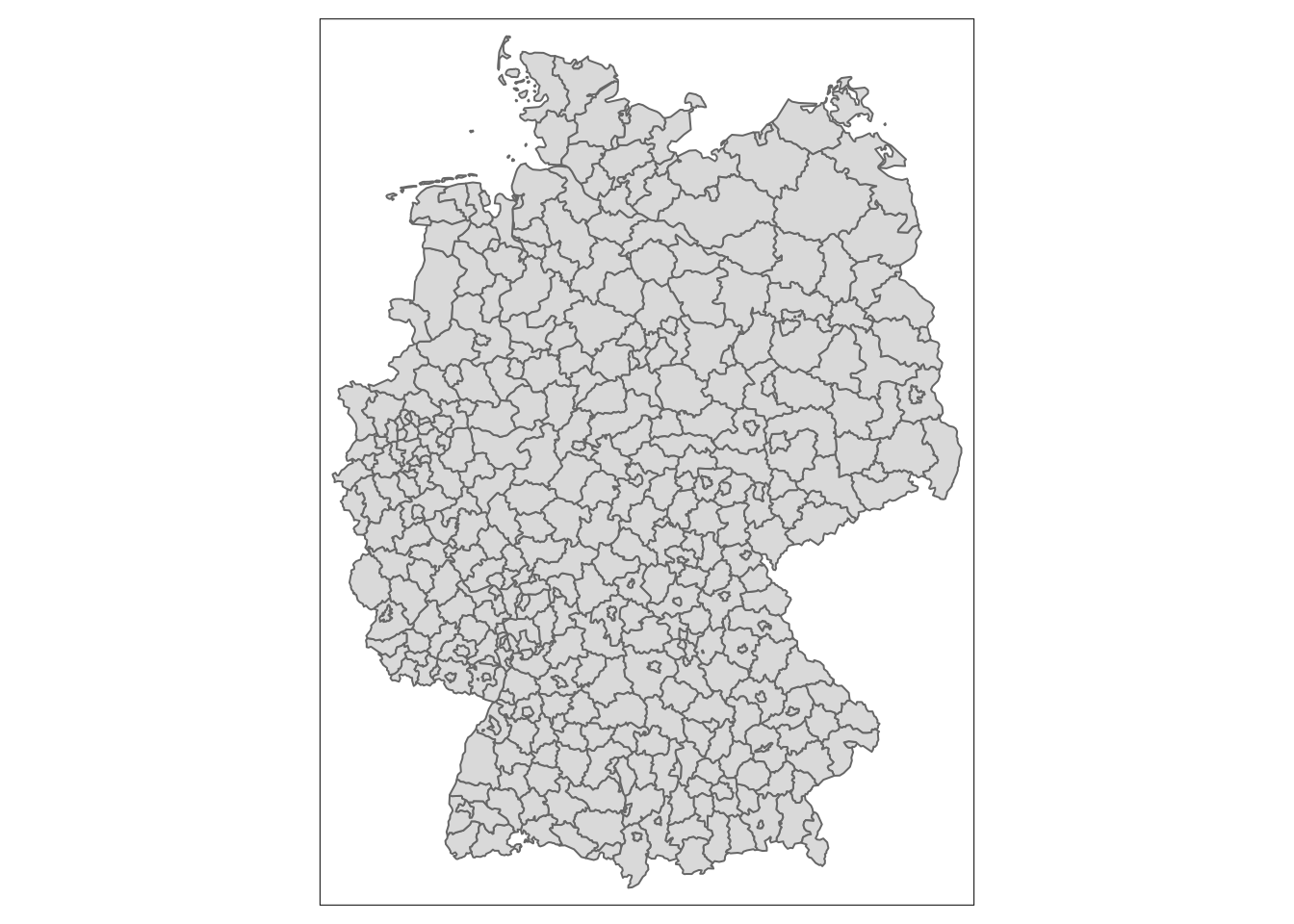
16.9 Räumliches Verschneiden
mit st_join werden Datensätze nicht mit einem Key verschnitten, sondern anhand ihrer Geolokation. Dann können wir wieder ganz normal group_by und summarise verwenden:
st_join(kreise, preise_sf) %>%
group_by(NUTS_ID) %>%
summarise(dieselpreis = median(dieselpreis),
e5preis = median(e5preis),
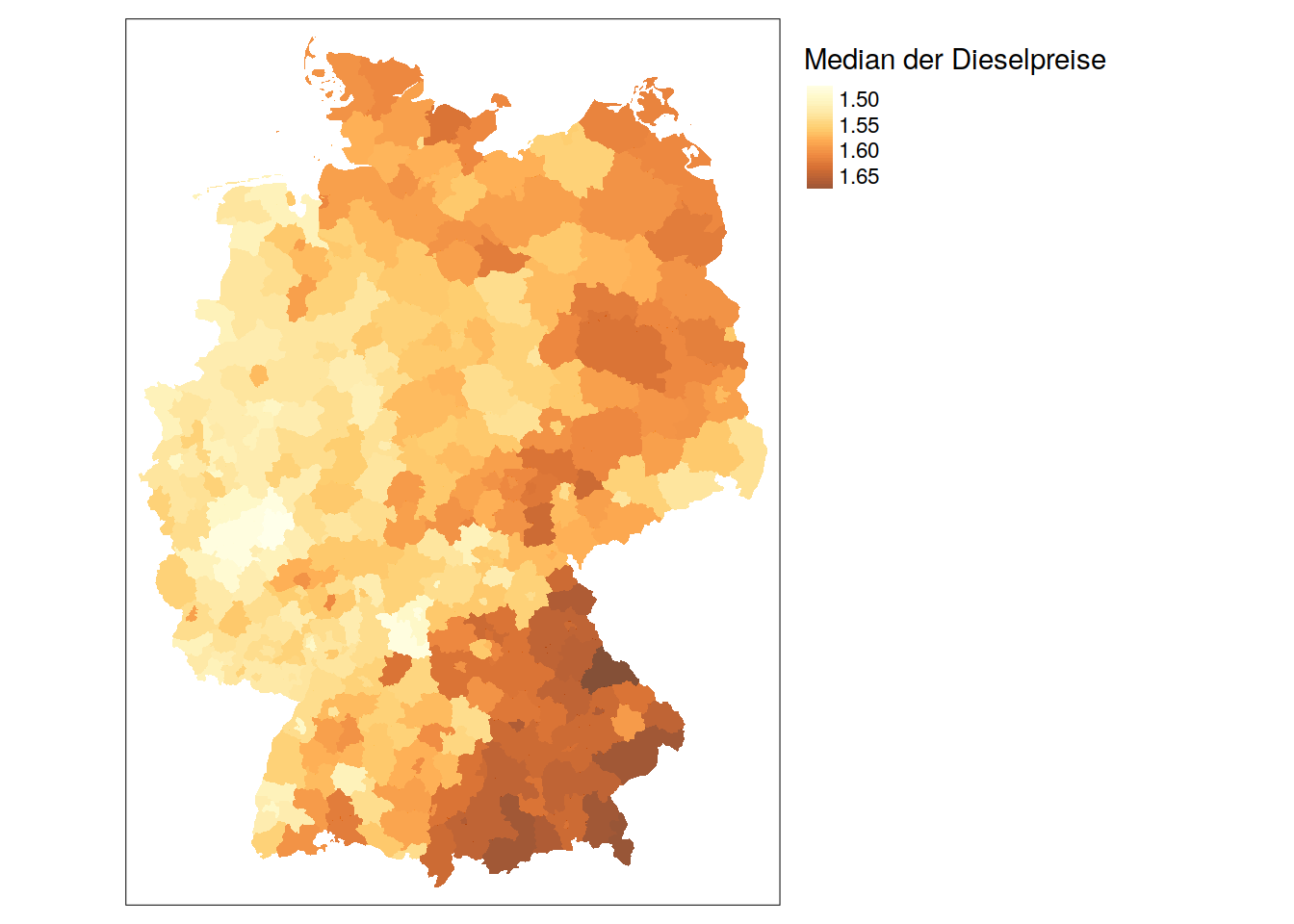
e10preis = median(e10preis)) -> preise_kreiseUnd so könnte vielleicht ein vorläufiges Ergebnis aussehen:
tm_shape(preise_kreise) +
tm_fill("dieselpreis",
title = "Median der Dieselpreise",
style = "cont",
alpha = 0.8) +
tm_layout(legend.outside = TRUE)