Sitzung 22 Clusteranalyse
22.1 Voraussetzungen
library(tidyverse)
library(plotly)
library(ggdendro)22.2 Datensatz und Überblick
Mitgeliefert in R ist ein beliebter Beispieldatensatz mit Daten aus einem Automagazin:
data(mtcars)
head(mtcars)
## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1Im Folgenden geht es um die technischen Aspekte einer Clusteranalyse, und diese Daten dienen zur Veranschaulichung.
Einen ersten Überblick über den Datensatz kriegen wir mit:
summary(mtcars)
## mpg cyl disp hp
## Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
## 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
## Median :19.20 Median :6.000 Median :196.3 Median :123.0
## Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
## 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
## drat wt qsec vs
## Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
## 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
## Median :3.695 Median :3.325 Median :17.71 Median :0.0000
## Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
## 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
## Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
## am gear carb
## Min. :0.0000 Min. :3.000 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
## Median :0.0000 Median :4.000 Median :2.000
## Mean :0.4062 Mean :3.688 Mean :2.812
## 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
## Max. :1.0000 Max. :5.000 Max. :8.000Oder mit Scatterplots in verschiedenen denkbaren Variationen:
ggplot(mtcars) +
geom_label(aes(x = mpg, y = disp, label = rownames(mtcars)), size = 3)
22.3 Clusteranalyse
Grundüberlegung der Clusteranalyse ist, in wie viele und welche Gruppen die Merkmalsträger (hier: die Autos) einer (multivariaten) Verteilung sinnvoll eingeteilt werden können. Dabei gibt es viele verschiedene mathematische Methoden – hier soll nur die Grundvariante (\(k\)-means-Clustering anhand euklidischer Distanz) besprochen werden.
Zunächst führen wir mit scale() eine \(z\)-Transformation aller Variablen durch, damit werden sie alle gleich stark gewichtet:
mtcars %>%
scale() %>%
head()
## mpg cyl disp hp drat
## Mazda RX4 0.1508848 -0.1049878 -0.57061982 -0.5350928 0.5675137
## Mazda RX4 Wag 0.1508848 -0.1049878 -0.57061982 -0.5350928 0.5675137
## Datsun 710 0.4495434 -1.2248578 -0.99018209 -0.7830405 0.4739996
## Hornet 4 Drive 0.2172534 -0.1049878 0.22009369 -0.5350928 -0.9661175
## Hornet Sportabout -0.2307345 1.0148821 1.04308123 0.4129422 -0.8351978
## Valiant -0.3302874 -0.1049878 -0.04616698 -0.6080186 -1.5646078
## wt qsec vs am gear
## Mazda RX4 -0.610399567 -0.7771651 -0.8680278 1.1899014 0.4235542
## Mazda RX4 Wag -0.349785269 -0.4637808 -0.8680278 1.1899014 0.4235542
## Datsun 710 -0.917004624 0.4260068 1.1160357 1.1899014 0.4235542
## Hornet 4 Drive -0.002299538 0.8904872 1.1160357 -0.8141431 -0.9318192
## Hornet Sportabout 0.227654255 -0.4637808 -0.8680278 -0.8141431 -0.9318192
## Valiant 0.248094592 1.3269868 1.1160357 -0.8141431 -0.9318192
## carb
## Mazda RX4 0.7352031
## Mazda RX4 Wag 0.7352031
## Datsun 710 -1.1221521
## Hornet 4 Drive -1.1221521
## Hornet Sportabout -0.5030337
## Valiant -1.1221521Dann wird mit dem dist()-Befehl anhand der vier Variablen eine „Distanz“ zwischen den Staaten berechnet, mit hclust() mögliche Cluster berechnet und mit ggdendrogram() eine Visualisierung von mögliche Clusteranordnungen ausgegeben:
mtcars %>%
scale() %>%
dist() %>%
hclust() %>%
ggdendrogram()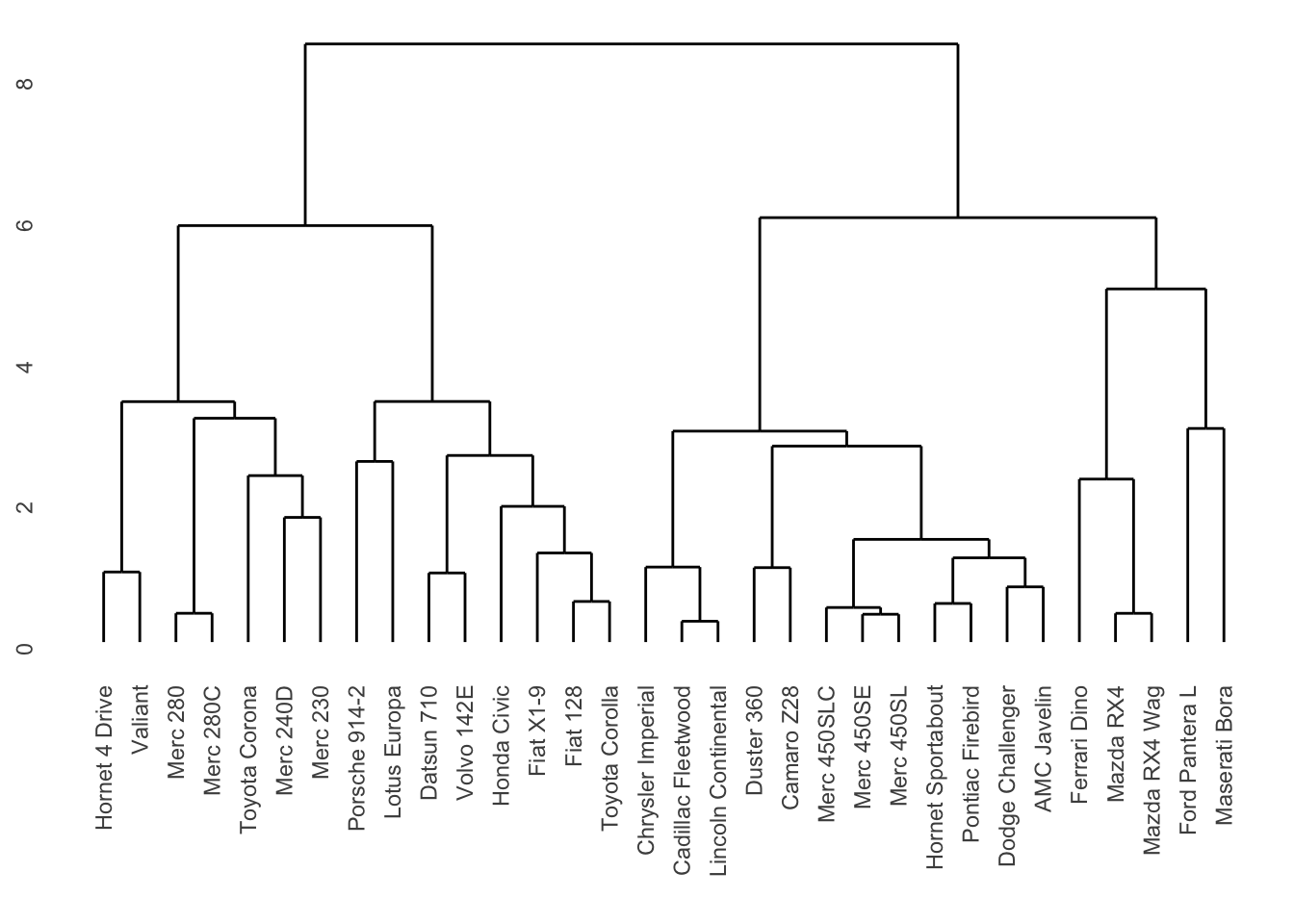
Dabei befindet sich auf der y-Achse die Distanz, bei der verschiedene Cluster zusammenfallen. Ganz unten sind es 32 Cluster mit je einem Staat, dann werden nach und nach Cluster zusammengefasst, bis es ganz oben nur noch ein Cluster mit 32 Autos ist. Je länger die parallelen Vertikalen Striche, desto beständiger die Cluster.
Hier würden sich vier oder fünf Cluster anbieten, wir entscheiden uns für 5 Cluster.
Mit kmeans() bilden wir die Cluster (nach \(z\)-Transformation) und können direkt Größe, Charakteristika und Mitglieder
der Cluster einsehen:
mtcars %>%
scale() %>%
kmeans(4)
## K-means clustering with 4 clusters of sizes 11, 4, 14, 3
##
## Cluster means:
## mpg cyl disp hp drat wt
## 1 0.98501724 -0.9194387 -0.9711844 -0.7472405 0.9058647 -1.00220367
## 2 0.15918090 -0.6649228 -0.6055161 -0.6700055 0.4973781 0.08968198
## 3 -0.82805177 1.0148821 0.9874085 0.9119628 -0.6869112 0.79918068
## 4 0.04027052 -0.4782778 -0.2395422 -0.6226038 -0.7790893 -0.17433904
## qsec vs am gear carb
## 1 0.01240056 0.3945581 1.1899014 0.7932015 -0.2778997
## 2 1.21786185 1.1160357 -0.8141431 0.4235542 0.1160847
## 3 -0.60248536 -0.8680278 -0.5278510 -0.5445697 0.4256439
## 4 1.14231385 1.1160357 -0.8141431 -0.9318192 -1.1221521
##
## Clustering vector:
## Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
## 1 1 1 4
## Hornet Sportabout Valiant Duster 360 Merc 240D
## 3 4 3 2
## Merc 230 Merc 280 Merc 280C Merc 450SE
## 2 2 2 3
## Merc 450SL Merc 450SLC Cadillac Fleetwood Lincoln Continental
## 3 3 3 3
## Chrysler Imperial Fiat 128 Honda Civic Toyota Corolla
## 3 1 1 1
## Toyota Corona Dodge Challenger AMC Javelin Camaro Z28
## 4 3 3 3
## Pontiac Firebird Fiat X1-9 Porsche 914-2 Lotus Europa
## 3 1 1 1
## Ford Pantera L Ferrari Dino Maserati Bora Volvo 142E
## 3 1 3 1
##
## Within cluster sum of squares by cluster:
## [1] 50.640639 8.273577 64.934413 3.996899
## (between_SS / total_SS = 62.5 %)
##
## Available components:
##
## [1] "cluster" "centers" "totss" "withinss" "tot.withinss"
## [6] "betweenss" "size" "iter" "ifault"Damit R die Clusterzugehörigkeit (1 bis 5) im Folgenden nicht als metrische sondern als nominalskalierte Variable versteht, ziehen wir sie aus dem Ergebnis heraus und wandeln sie in einen Factor um (s. [Exkurs Factors]).
mtcars %>%
scale %>%
kmeans(5) %>%
.$cluster %>%
factor() -> membershipsDiesen „faktorierten“ Cluster-Vektor fügen wir dem Datensatz hinzu:
mtcars_cluster <- mtcars %>%
scale %>%
as_tibble() %>%
mutate(cluster = memberships)22.4 Visualisierung
Die verschiedenen Cluster lassen sich dann z.B. farblich voneinander abgrenzen:
ggplot(mtcars_cluster, aes(x = wt, y = qsec, color = cluster)) +
geom_point() +
stat_ellipse()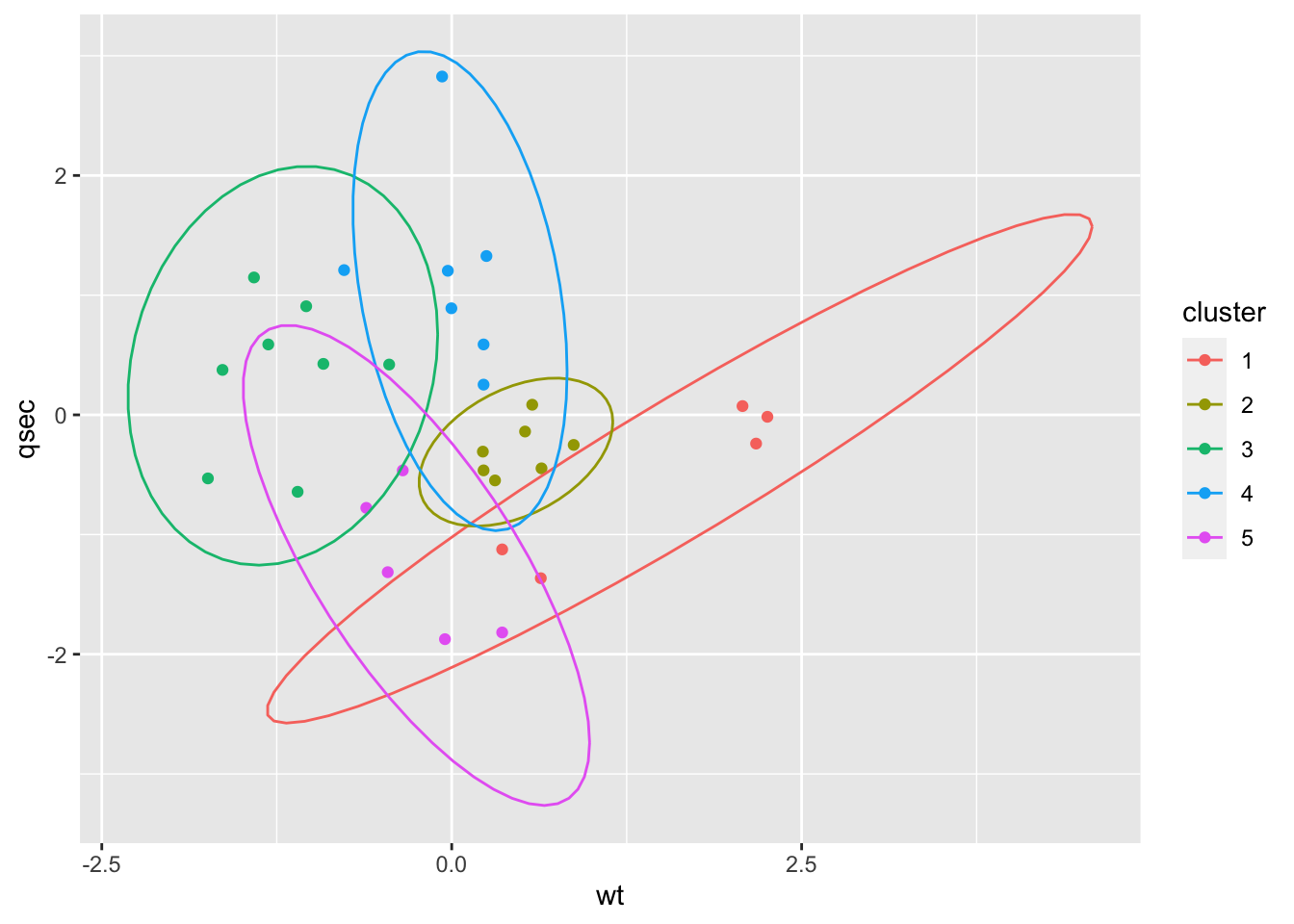
Zu einer Clusteranalyse würde dann auch noch gehören, die einzelnen Cluster anhand ihrer Charakteristika zu beschreiben.